

By Dr Albert Gatt from the Institute of Linguistics and Language Technology
There is a significant possibility that some of the text you read on a regular basis is written by a machine. At least some of the time, you might not realise this.
Natural Language Generation (NLG) involves the automatic linguistic summarisation of non-linguistic information (in the form of images, symbolic data, numbers, or any other format). In recent years it has become possible to scale up the technology in practical use-cases. For instance, it is now quite common for online weather reports to be automatically generated. Another example is automatic image captioning where, given an image, a system generates a description of its contents. In these and other cases, the non-linguistic input needs to be “interpreted” before being expressed linguistically.
That this technology has become robust enough to deploy in actual applications is in part due to recent advances in Artificial Intelligence (AI), especially the widespread adoption of neural networks as our fundamental learning algorithms.
Where’s my language?
One of the downsides of this is that these models, besides being very resource-hungry, need to be trained on vast amounts of data, which isn’t necessarily available for all languages. For instance, it’s unlikely that the weather reports we read in Maltese are automatically generated (not yet, anyway).
At the Institute of Linguistics and Language Technology (LLT), one of our goals is to extend the reach of current technologies for language processing (not just NLG, but also Automatic Speech Recognition and Natural Language Understanding) to handle “under-resourced” languages.
This has an ethical dimension, insofar as AI needs to be harnessed in favour of diversity and democratisation, rather than being a force for increased homogeneity. But it also raises important scientific questions, such as whether we can develop technologies that can do more with less, or are able to transfer knowledge between related languages. There might after all be something in the statement, beloved of us linguists, that languages have a lot in common despite their diversity.
What did the machine mean?
It turns out that the opening statement to this piece might have been somewhat exaggerated. Beyond comparatively simple texts like weather reports, it is often not hard to detect when the text before us was produced by a machine (readers may wish to verify this by taking this state-of-the-art neural generator for a spin). This is because we are still grappling with problems such as relevance and accuracy (ensuring that the output text really expresses what is in the input), while also dealing with the bewildering expressive arsenal of natural languages.
Given the above, I believe it is still important to sometimes take a step back from a pure machine-learning approach to language, and focus some of our efforts on accurate mathematical modelling of the underlying semantics of linguistic expressions. As an example, consider the map below (showing the region of Galicia in Spain).
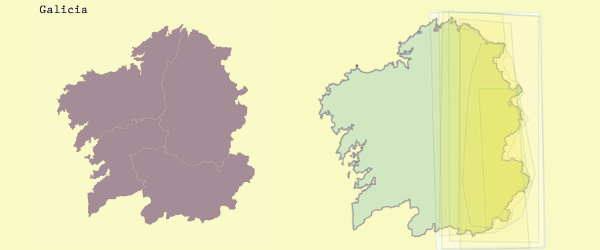
Suppose that a weather reporting system told you that it would rain in the East. Where does the East begin, and how far does it extend? (No doubt, this is a question that historians and international relations experts have had to grapple with, albeit for very different reasons.) In some recent work, a collaboration between the LLT and the University of Santiago de Compostela, we tried to fine-tune a generator by showing readers, including expert meteorologists, maps and corresponding geographical expressions, asking them to draw a polygon around the relevant region on a map. A more detailed discussion of this work can be found in this paper, among others.
The outcome, shown in the image on the right, evinced considerable diversity in the interpretation of phrases such as ‘Eastern Galicia’. In short, the meaning of such phrases is fuzzy: there is a central “core” which all the polygons contain, but also a periphery which is included in the meaning of the expression to different degrees. The tools of fuzzy set theory are designed to handle this sort of vagueness: the idea is that there is a core set of coordinates which we are 100% sure belong in the “East”, with membership degrading gracefully as we move away from that core.
Such explicit semantics allow us to control what generators output and do justice to some of the complexities of meaning.
What’s next?
The future of technologies such as NLG lies in increasingly sophisticated machine-learning methods, but controlling the output of our systems will probably also require us to consider empirically-grounded formal models of language. One benefit of this might be an increased ability to make our systems “explainable” to users, who not only have a right to be informed of the provenance of what they are reading, but also to be able to evaluate it.
At the UM, there is now a significant critical mass of researchers working in technologies related to language, from both a generation and an understanding perspective, not only in the LLT, but also in the Faculties of Science, ICT, Engineering and MAKS. Our research at the LLT is thus embedded in a very broad collaborative network, both locally and internationally. This pooling together of resources is itself an important part of the future of the field.


